Near-Human Quality Neural Machine Translation for Public Administrations
Easy, Deployable, Customized
really-simple-ssl domain was triggered too early. This is usually an indicator for some code in the plugin or theme running too early. Translations should be loaded at the init action or later. Please see Debugging in WordPress for more information. (This message was added in version 6.7.0.) in /home/jmtafp/public_html/wp-includes/functions.php on line 6114wpforms-lite domain was triggered too early. This is usually an indicator for some code in the plugin or theme running too early. Translations should be loaded at the init action or later. Please see Debugging in WordPress for more information. (This message was added in version 6.7.0.) in /home/jmtafp/public_html/wp-includes/functions.php on line 6114NTEU will create and release near-human quality machine translation engines built on industry tested neural networks technologies to/from all official EU languages except English. It will gather massive amounts of data to obtain a minimum of 15M viable sentences for training in well-resourced language pairs, slightly less in under-resourced languages. State-of-the-art methods will be applied to gather and clean data and train direct-language neural engines. Parallel corpora will be delivered to European data- gathering efforts such as ELRC and ELRC-Share.
Training data sets will be available Public Administrations and CEF.AT as translation memories. Partners will deliver ready-made engines fully dockerized so they can be easily deployed as national infrastructures. Public Administrations will be able to call the engines and obtain private, high-quality direct-combination neural machine translation. Whether they need private machine translation or services to the public, NTEU will make it possible to offer ultra-fast near-human quality machine translation to improve citizen’s lives, transactions among different European administrations or process information privately.
NTEU’s goal is not only to deliver ready-made technology. There will be a final, large parallel corpora release including all training segments into all language pairs. This will ensure scalability and re-use once the project is over. Future technologies will be able to re-use NTEU’s data sets to upscale their machine learning algorithms with the Action’s data.
This action will build upon other Actions’ ongoing efforts to collect data from 23 official EU languages. It will crawl, align, ingest word-processing and PDFs, re-use material from other Actions such as Paracrawl, NEC-TM, DGT material, etc. It will also create highly scalable synthetic material to support machine learning. We expect to create the largest parallel corpus between EU official languages, focusing on the needs of CEF-AT and European Public Administrations.
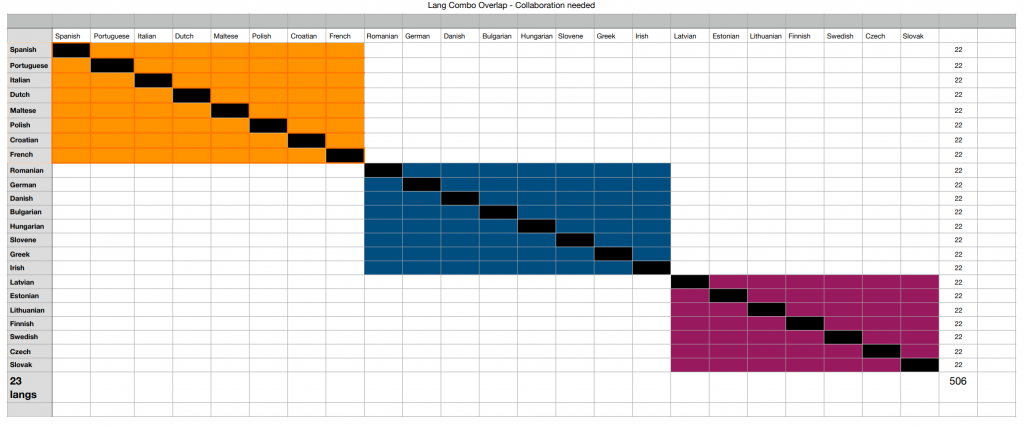
The NTEU project will create the largest ever direct language-to-language engine combination
Further information: https://nteu.eu/about-nteu-why-neural-machine-translation-for-public-administrations/
